PP-A: Code-based Parallelization
Current auto-parallelization techniques performed by compilers are too conservative because the compile-time (static) knowledge of data dependencies is insufficient. In contrast, optimistic approaches based on actual (dynamic) dependencies have shown to allow reproduction of manual parallelization strategies, but
- the risk of missing dependencies requires final validation by the user
- the acquisition and analysis of dependencies poses a hard challenge for realistic programs.
The goal of this part project is to advance the optimistic parallelisation approach such that it becomes applicable to realistic use cases on systems with shared memory. A particular focus is to apply the developed techniques to software used in high-performance computing.
To achieve applicability in real world scenarios the following points have to be addressed:
- improved understanding of the effects of defective and incomplete dependency information,
- development of conditional correctness guarantees in the presence of incomplete, empirically determined dependency information,
- exploitation of further parallelization potential, in particular, support for a broader range of parallel design patterns,
- higher degree of automatization for the parallelization process and increased efficiency of the underlying program analyses.
The optimistic parallelisation approach is divided into the four steps shown below:
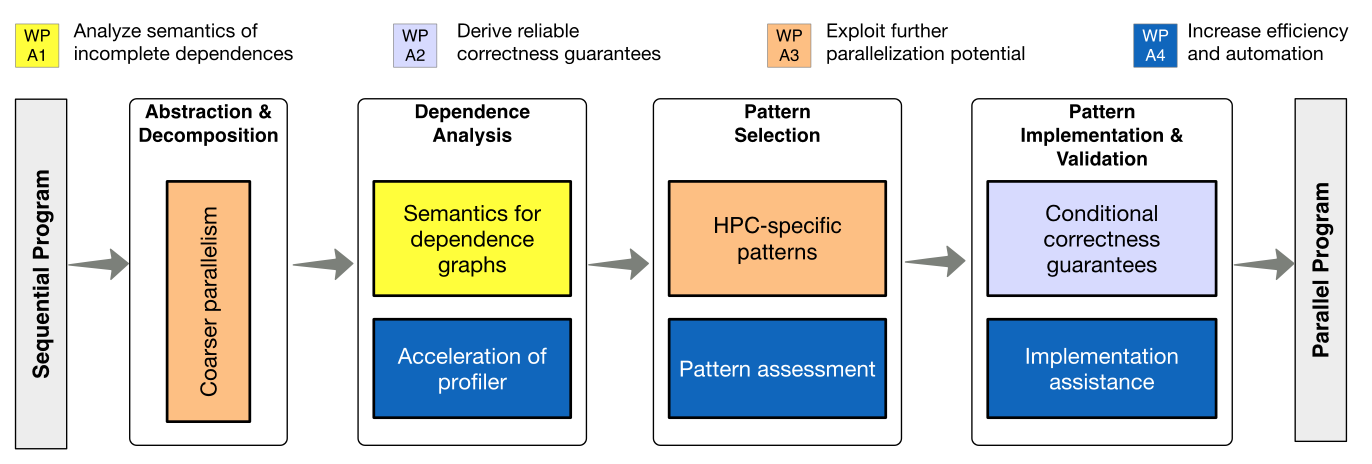
First, the source code is abstracted into a suitable intermediate representation, which is then decomposed into short code sequences without any significant internal parallelisation potential. Then, the dependencies between these code sequences are statically and dynamically analysed. After that, design pattern suitable for parallelisation are derived from the dependency graph and the most promising patterns are selected. The implementation of the pattern shall be performed semi-automatically, with extensive support being offered to the programmer. Validation is performed by inspection and tests based on the source code and the correctness conditions extracted from the dependency graph.