TP-A: Codebasierte Parallelisierung
Aktuelle automatische Parallelisierungstechniken, die von Compilern durchgeführt werden, sind zu konservativ, da das statische Wissen über Datenabhängigkeiten zur Kompilierungszeit nicht ausreichend ist. Dem gegenüber stehen optimistische dynamische Ansätze, basierend auf erkannten dynamischen Abhängigkeiten, die eine manuelle Anwendung von Parallelisierungsstrategien erlaubt.
Allerdings
- wird durch das Risiko von fehlenden Abhängigkeiten eine Validierung des Nutzers benötigt
- ist das Zusammenstellen und Analysieren von Abhängigkeiten eine schwierige Aufgabe für realistische Programme.
Das Ziel dieses Teilprojektes ist die Weiterentwicklung des Ansatzes der optimistischen Parallelisierung, um diesen auf realistische Programmen und Systeme mit geteiltem Speicher anwenden zu können. Ein spezieller Fokus ist die Anwendung der entwickelten Techniken im Bereich des High Performance Computing.
Um die Ansätze in realen Szenarios anwenden zu können, müssen die folgenden Punkte umgesetzt werden:
- eine Verbesserung des Verständnisses der Effekte von falschen und unvollständigen Abhängigkeitsinformationen,
- eine Entwicklung von bedingten Korrektheitsgarantien bei der Nutzung von unvollständigen und empirisch ermittelten Abhängigkeitsinformationen,
- eine bessere Ausnutzung von Parallelisierungspotential der Software, insbesondere durch Unterstützung von weiteren parallelen Entwurfsmustern, sowie
- eine höherer Automatisierungsgrad des Parallelisierungsprozesses und eine erhöhte Effizienz der genutzten Programmanalysen.
Der optimistische Parallelisierungsansatz ist in die dargestellten vier Schritte unterteilt:
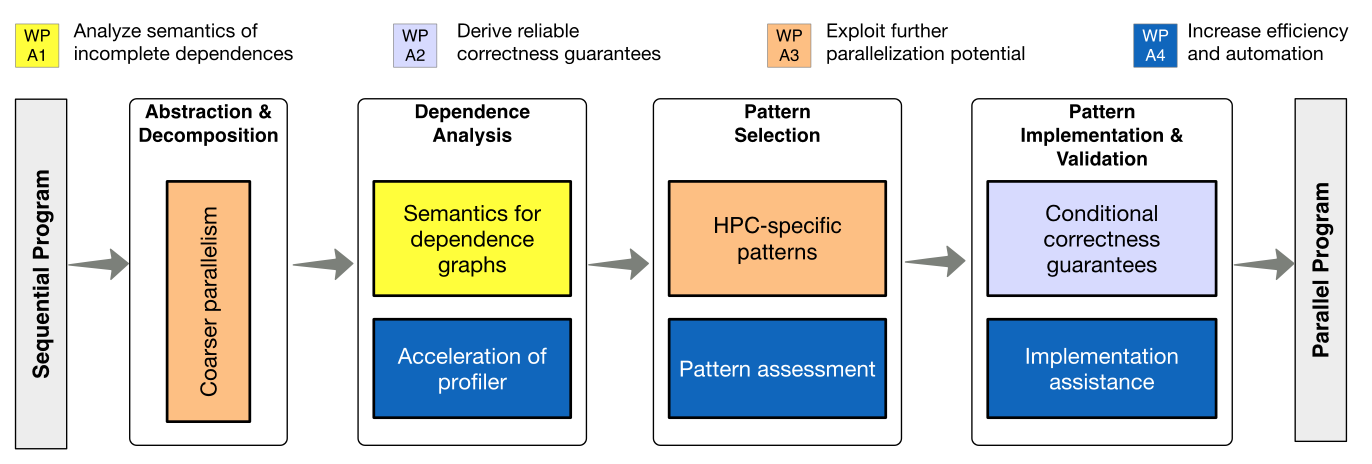
Zuerst wird der Quellcode in eine geeignete Zwischendarstellung abstrahiert, welche dann in kleine Codestücke unterteilt wird, die einzeln betrachtet kein nennenswertes Parallelisierungspotential besitzen. Danach werden die Abhängigkeiten zwischen den Codestücken statisch und dynamisch analysiert. Anschließend werden geeignete Entwurfsmuster zur Parallelisierung aus dem Abhängigkeitsgraphen erkannt, gewichtet und selektiert. Die Implementierung der Entwurfsmuster soll halbautomatisiert erfolgen, wobei dem Entwickler eine umfangreiche Hilfe geboten wird. Die Validierung wird durch Codekontrolle sowie durch Tests durchgeführt, die auf Korrektheitsbedingungen basieren, die aus dem Abhängigkeitsgraphen abgeleitet werden.